

{kind=link}
Have you ever wondered how a machine gets better by learning from its mistakes? Researchers created a system called back propagation neural networks (that is, computing setups that adjust themselves by learning from errors) that works a lot like a musician tuning his instrument.
This method looks for hidden patterns in huge piles of data and improves its guesses each time it runs through them. In a way, back propagation is the engine that helps smart gadgets make even smarter decisions.
In this piece, we'll take you through each step of the process and show you how it transforms raw data into clear, useful insights that spark innovation.
Understanding Back Propagation Neural Network: Core Mechanism and Intuition
Back propagation is the heartbeat of multilayer perceptron training. It starts with random settings for each weight and bias, then learns by correcting its mistakes. Imagine tuning a guitar slowly until every chord sounds just right. That’s how the network refines its predictions, gradually uncovering complex patterns hidden in the data.
In the first step, called the forward pass, data moves from the input layer through hidden layers to the output layer. At each stage, the network calculates a weighted sum of the inputs and adds a bias, then uses an activation function (a simple rule that decides the next step) to produce a result. This output is compared to the expected answer, setting the stage for learning. Next comes the backward pass, where the network figures out the error between its guess and the target, using a method known as the chain rule (a way to work out how much each part contributes). It then finds key gradients for various weights and biases, paving the way for smart updates.
After these gradients are determined, the network tweaks its parameters bit by bit. With each update, it subtracts a bit of the gradient multiplied by the learning rate (a factor that controls the step size). It’s a bit like gradually adjusting the focus on a camera until the image is crystal clear. This process repeats over and over until the network gets really good at predicting outcomes, showcasing back propagation as a core iterative approach to fine-tuning neural networks.
back propagation neural network sparks smart innovation
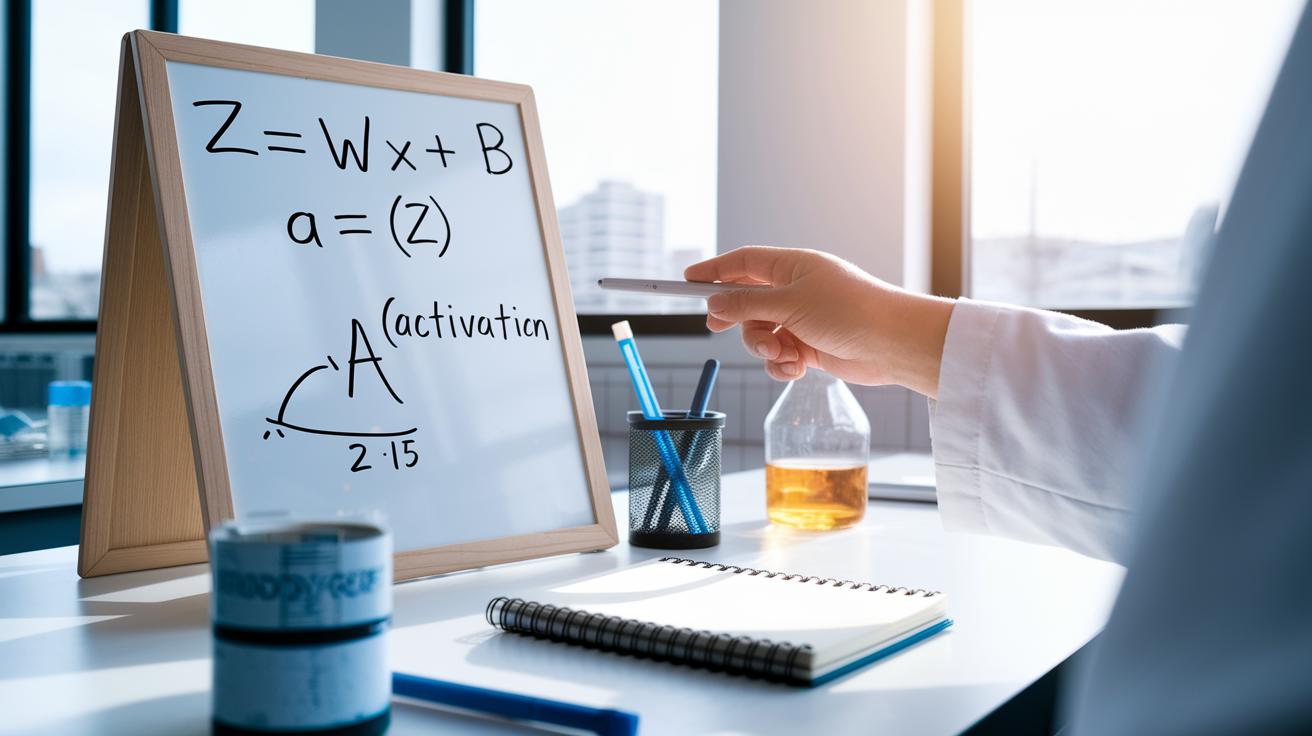
At its core, back propagation is all about using math to turn raw data into smart guesses. It starts with a simple linear equation: Z = W·X + b. Here, W stands for the weights (which control the influence of each input), X is the input data, and b is the bias (a number we add to fine-tune the result).
Then comes the activation function, which is written as A = σ(Z). This step changes the straight-line output into a wavy, non-linear signal. Usually, σ is the sigmoid function, a tool that squishes numbers into a range between 0 and 1. Think of it like adjusting the brightness on a screen, making sure values never get too high or too low.
We check how well our network is doing with something called the mean squared error cost function, shown as J = (1/2)(Ŷ – Y)². In simple terms, it compares the network’s guess (Ŷ) to the real answer (Y) and figures out the difference. This difference helps us know how much to tweak our model.
Imagine calculating a weighted sum a bit like (0.2 × 0.35) + (0.2 × 0.7) to get a number before it goes through the activation phase. Because we use vectorized equations, these operations work even when our network handles lots of neurons at once.
Next, the multivariate chain rule steps in. This rule is like a detective, figuring out which weight or bias is causing the error by calculating partial derivatives. This process allows the network to adjust each parameter with precision, much like tuning a guitar so each string sounds just right.
| Gradient Term | Formula |
|---|---|
| dZ | A – Y |
| dW | (1/m)·(dZ·A_prevᵀ) |
| db | (1/m)·Σ dZ |
By applying these formulas, back propagation smartly guides adjustments to weights and biases. It figures out just how much each small change affects the error, allowing the network to steadily improve its accuracy with each pass. It’s like fine-tuning a musical instrument; every little tweak brings everything closer to perfect harmony.
Stepwise Algorithm of Back Propagation Neural Network
The back propagation process works in three clear steps: first, data goes forward through the network; then, we trace errors backward; and finally, we fine-tune the weights. It’s a bit like experimenting in the kitchen, each step builds on the last until you get the perfect recipe.
Forward Pass
Data starts at the input and makes its way to the output. At every neuron, it gets mixed with weights and biases to create a sum, which then goes through an activation function. Think of it like a chef following a trusted recipe: a few basic ingredients come together, layer by layer, to transform raw numbers into useful insights.
Backward Pass
After the forward pass, we see the difference, or error, between what the network predicted and what it should have predicted. Using a method from calculus called the chain rule (a step-by-step guide to breaking things down), we work our way back through the network. This helps us understand how much each weight and bias (the dW and db values) contributed to the error. It’s similar to retracing your steps after a misstep in a new recipe to figure out what went wrong.
Weight Update
Finally, we adjust the weights and biases using the gradients we just calculated. We do this with an update rule that looks like this: W becomes W minus a small portion of dW (using a learning rate, or how quickly we update). You can picture this like tweaking a recipe gently based on feedback until it tastes just right. Each tiny change refines the network’s performance, turning rough ideas into brilliant insights.
Implementing Back Propagation Neural Network in Python

In this section, we take a friendly dive into a simple Python example that uses NumPy to crack the classic XOR problem with a little neural network. Imagine a setup where two input values go into a hidden layer with four neurons, and then the network gives you one output. The magic happens over 10,000 practice rounds (epochs) with a learning rate of 0.1, which helps the network gradually learn the patterns.
Our example uses the sigmoid function (a smooth curve that squishes numbers into a range between 0 and 1) to add a touch of nonlinearity. First, the feed_forward() function mixes the inputs by calculating Z = W·X + b, and then it applies the sigmoid to roll out those activations. Next, back_propagate() figures out the error using the Mean Squared Error (a simple way to measure mistakes) along with the slope of the sigmoid, so it knows which weights and biases need a little nudge. Finally, update_weights() makes those adjustments by subtracting a slice of the calculated gradients from what we currently have.
This step-by-step setup makes it pretty clear how the network learns over time, letting us see each part of the process all laid out nicely.
Key parts of the code include:
- Network initialization with random weights and biases
- Forward pass function computing Z and A
- Backward pass and weight update routine
Addressing Challenges in Deep Back Propagation Neural Network
Deep back propagation networks can run into some tricky issues. One common problem is when gradients become too tiny, especially if you use the sigmoid function in many deep layers. When these gradients shrink, the network can’t adjust the early layers properly. This means the model may not learn as well as it could. Another issue is the heavy computational cost, which slows down training and makes it tougher to try out new ideas quickly. In real-world practice, these challenges might cause the model to either memorize the training data (overfitting) or miss important patterns (underfitting). Luckily, there are some practical steps you can take to smooth things out for a more reliable training process.
| Technique | Description |
|---|---|
| Xavier/He weight initialization | This method helps kick off training with more balanced weights, reducing early pitfalls. |
| L2 regularization on weights | A simple approach to prevent the model from leaning too hard on any one weight. |
| Dropout between layers | This technique randomly “drops out” some neurons, helping the network stay flexible and avoid overfitting. |
| Batch normalization after activations | It keeps the outputs of each layer in check, which can speed up and stabilize learning. |
| Adaptive learning rates (e.g., Adam) | This adjusts the step size during training so the model learns at the right pace, not too slow or too fast. |
By putting these strategies to work, you can really ease the rough spots in deep neural network training. Better weight initialization gives the model a strong start. Regularization and dropout help prevent the network from getting overly dependent on any one part. Batch normalization makes sure everything stays balanced, and adaptive learning rates help the network tune itself perfectly. Taken together, these techniques create a smoother learning process, making it easier for deep networks to overcome their natural challenges and pull out useful insights from data.
Variants and Enhancements of Back Propagation Neural Network

Back propagation training has become a lot more efficient thanks to new optimizers that really fine-tune how the network learns. You might start with the classic stochastic gradient descent (SGD), where the learning rate stays constant. It’s easy to use, but add a momentum term, essentially a push that carries updates along, and the process speeds up because the updates become smoother. Then there’s RMSprop, which adjusts the learning rate using a moving average of recent gradients (basically, it watches how errors change) to tackle tricky, noisy problems. Adam mixes these ideas by using both first- and second-moment estimates (think of these as keeping track of simple averages and their variations) to tweak step sizes dynamically. These smart techniques make handling complex networks and varied data a lot simpler, resulting in more stable and faster training.
It helps to compare these methods so you can pick the best one for your needs. Many choose SGD for its simplicity or when computer power is tight. But when gradients change or data shifts subtly, RMSprop handles it better. Adam has become a popular all-rounder, offering balanced performance with smoother updates that cut down on wild swings during training. The table below offers a clear, side-by-side look at these four optimization strategies.
| Optimizer | Key Feature | Benefit |
|---|---|---|
| SGD | Constant learning rate | Simplicity |
| SGD+Momentum | Momentum/velocity term | Faster, smoother convergence |
| RMSprop | Adaptive learning rate | Handles changing or noisy data |
| Adam | Moment estimates for adjustment | Balanced, robust performance |
Applications of Back Propagation Neural Network in Modern AI Systems
Back propagation is a key method that trains many modern AI systems. Think of it like adjusting the focus on a camera lens, it fine-tunes the hidden filters (the small parts that pick out details) in a network, so the machine can see textures, edges, and patterns more clearly. Each layer in a convolutional network works a bit like a dedicated team, each refining the image in its own way.
When the filters get updated through back propagation, it's similar to making sure every piece of a puzzle matches perfectly. This process is super important in jobs like recognizing objects in images or sorting them into groups because the network must tell the difference between even the tiniest variations. Every layer, from start to finish, helps deliver a precise output.
Beyond just images, back propagation is a handy tool across many types of AI. In deep residual networks, for example, it passes the error signal back through all the layers so that each one learns what’s needed. And in deep reinforcement learning, back propagation tweaks the model's weights so the system can learn to make better decisions in changing environments.
Overall, this technique doesn't just adjust inner workings, it helps AI systems handle real-world tasks with better precision and steadiness. Have you ever been amazed by how a simple adjustment can lead to such smart outcomes? It's like watching a magic trick unfold, one deliberate step at a time.
Future Directions for Back Propagation Neural Network Research

Researchers are now exploring new ways to train neural networks beyond the standard back propagation. They're trying out second-order methods that use curvature details (think of it like understanding the shape of a learning path) to potentially speed things up. People are also taking a page from how our brains work, studying brain-like learning rules to see if they can help neural networks adapt more naturally to complex data. Next, they’re putting these ideas to the test with careful benchmarks to see if these methods can match or even beat the current best ways we adjust weights step by step.
Another exciting approach involves mixing back propagation with evolutionary strategies. This hybrid method combines the systematic flair of gradient-based learning with the wide-ranging search capabilities of evolutionary techniques. The idea is to avoid the trap of local minimums and build models that can adapt more robustly. There are plenty of open questions about the best ways to blend these diverse learning rules, setting the stage for some really promising future research in neural networks.
Final Words
In the action of our discussion, we unpacked how the back propagation neural network works, from calculating weighted sums to backpropagating error gradients and updating weights. We touched on the math behind it and even explored a Python script example that makes it all real.
We also looked at practical ways to handle challenges and improve performance. The insights shared offer a clear and friendly take on complex tech, leaving us excited about the future of innovation.
FAQ
What is the backpropagation algorithm and its formula?
The backpropagation algorithm trains networks by calculating error gradients. Its formula involves computing dZ = A – Y, then using derivatives for weights (dW) and biases (db) to update parameters and reduce the loss.
What are some examples of back propagation neural network implementations in Python and on GitHub?
The Python example of a back propagation network often uses NumPy for tasks like solving XOR problems. GitHub hosts projects that demonstrate network initialization, forward passing, and gradient-based weight updates.
Is back propagation still relevant in deep learning?
Back propagation remains crucial in deep learning. It drives the training of multilayer perceptrons by efficiently updating weights through gradient computation, making it a key method for current neural network models.
What are the key steps of back propagation?
The key steps include a forward pass to compute activations, a backward pass to derive error gradients, and a weight update step where adjustments use a learning rate to improve network performance.
Do CNNs use backpropagation?
CNNs employ backpropagation to train their layers. Error gradients are passed backward through convolutional layers, which then refine filter weights to enhance feature extraction and overall performance.
Does the brain use backpropagation?
The brain does not use backpropagation the way neural networks do. Biological learning involves more intricate, non-linear processes rather than systematic gradient-based weight adjustments.
Where can I find a back propagation neural network PDF?
Back propagation neural network PDFs are available on academic websites and educational repositories, offering detailed insights into the algorithm’s mechanics and mathematical foundations.