

{kind=link}
GPT‑4.5 stole the headlines, but a quieter wave of engineering and model releases slipped under the radar — and they matter. Cloudflare open‑sourced an AI Agent framework that persists state, runs tasks, browses the web and calls models in real time, enabling long‑lived assistants. Inception (a Stanford‑founded startup) introduced Mercury Coder, a diffusion‑based language model claiming 5–10× faster generation at 1,000+ tokens/sec. LangChain shipped LangGraph Swarm for coordinated multi‑agent systems. Jina launched LLM‑as‑SERP to produce search‑style result pages. Microsoft released Phi‑4‑multimodal and Phi‑4‑mini, compact models for multimodal and text workloads. These moves push AI toward faster, more modular, and more transparent applications.
Cloudflare Drops an Open‑Source AI Agent Framework

Cloudflare quietly released an open-source AI Agent framework designed for building persistent, web-aware agents. It supports state persistence, task execution, web browsing, and real‑time calls to AI models, enabling agents that don't forget context between runs. For developers, that means easier composition of long‑running assistants that integrate browsing, APIs, and model inference without vendor lock‑in. Because it's 100% open‑source, teams can inspect, extend, or self‑host components for security‑sensitive deployments. Expect this to accelerate production agent use , from automated research assistants and monitoring bots to customer service agents that maintain memory across sessions.
Mercury Coder: Diffusion‑Based LM That Writes 5–10× Faster

Inception, a startup founded by a Stanford professor, released Mercury Coder , the first commercial diffusion‑based language model promising dramatic throughput improvements. According to the company, Mercury Coder generates text 5–10× faster than standard autoregressive LLM decoders, hitting over 1,000 tokens per second on typical hardware. Diffusion‑based decoding reshapes sampling and enables parallelism that can cut latency and infrastructure cost. That’s huge for real‑time uses like code completion, live chat, and streaming content generation. The key questions now are adoption, benchmark parity with established LLMs, and real‑world quality at scale.
LangGraph Swarm: LangChain’s Lightweight Multi‑Agent Library
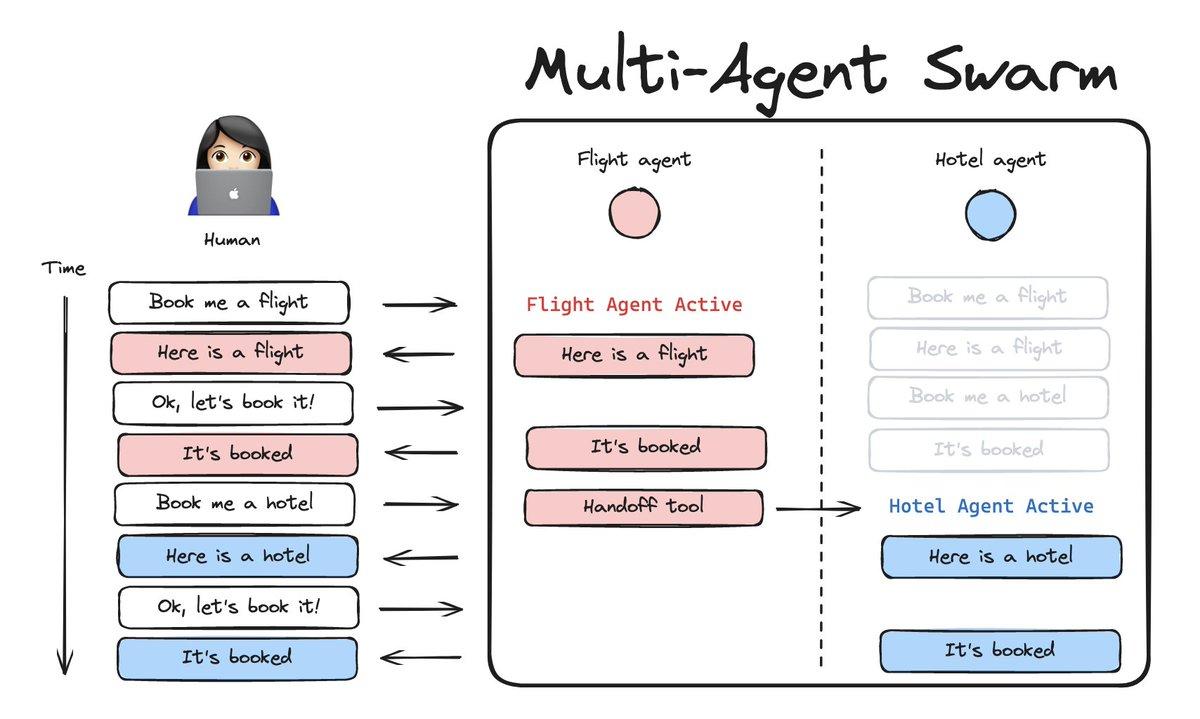
LangChain released LangGraph Swarm, a compact Python library built on LangGraph to create swarm‑style multi‑agent systems. The concept: spin up many small, specialized agents , searchers, reasoners, summarizers, tool‑callers , and dynamically hand off control to whichever agent best fits each subtask. That avoids a single monolith trying to do everything, improving modularity, parallelism and maintainability. Because it’s lightweight and Python‑friendly, LangGraph Swarm is ideal for prototyping collaborative AI pipelines and complex task orchestration. It integrates with common model calls, tool wrappers and retrieval systems, making it straightforward to build RAG‑enabled agents that query knowledge bases and pass evidence between experts.
LLM‑as‑SERP: Jina AI Turns LLM Output into Search Result Pages
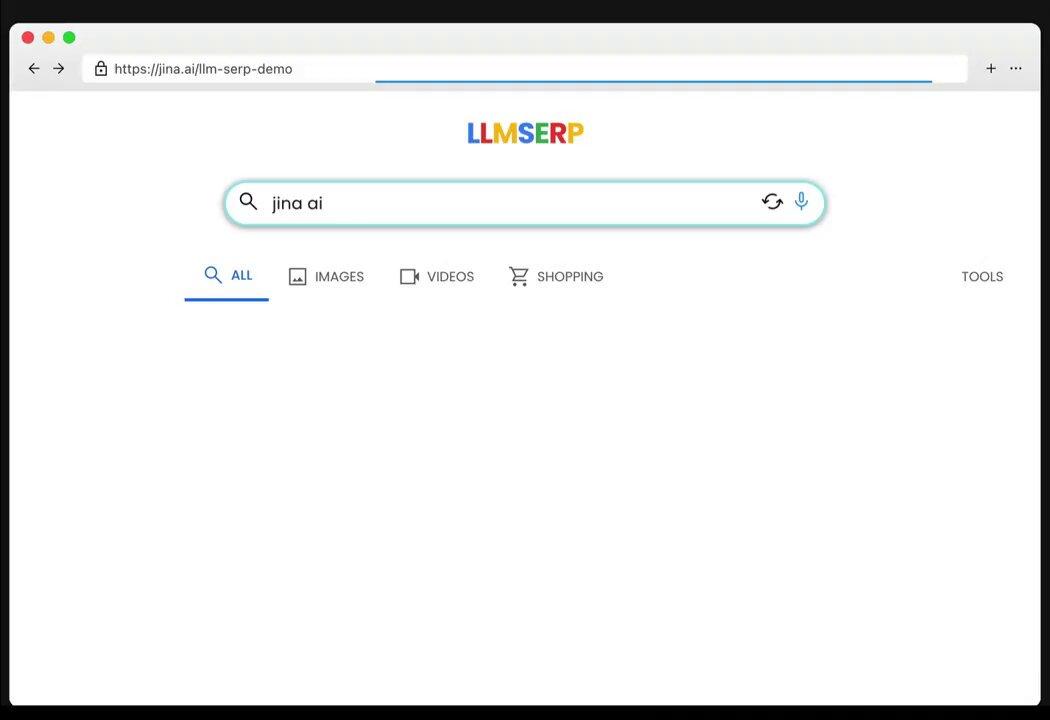
Jina AI rolled out LLM‑as‑SERP, an approach where an LLM generates a search‑engine style results page , complete with titles, links and snippets , instead of a single declarative answer. That reframes the model’s role from a binary knowledge test into a ranked, evidence‑weighed presentation. For retrieval‑augmented workflows and knowledge work, LLM‑as‑SERP increases transparency: users can inspect sources, compare snippets, and follow links back to evidence. This format helps reduce blind hallucination and improves trust when models summarize or answer complex queries. Expect it to show up in research assistants, enterprise search and interfaces that require traceable outputs.
Phi‑4 Family: Microsoft’s Compact Multimodal and Mini Text Models
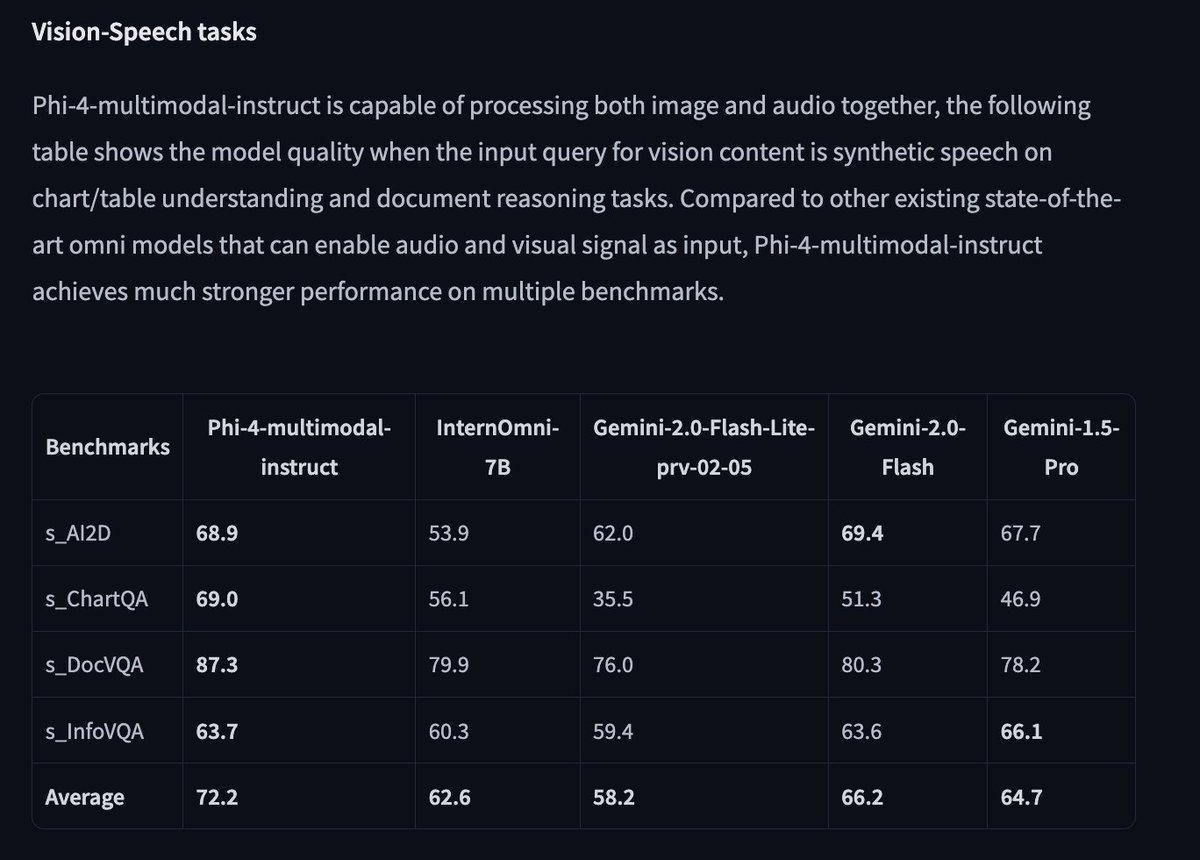
Microsoft expanded its Phi family with Phi‑4‑multimodal (5.6B) and Phi‑4‑mini (3.8B). The multimodal Phi‑4 integrates speech, vision and text in a compact architecture aimed at apps that need combined understanding , think voice+vision assistants or on‑device multimodal analytics. The 3.8B mini is tuned for text tasks , reasoning, math, coding and function calling , offering a smaller, faster model option when latency and cost matter. These releases reflect an industry shift toward efficient, capable models for constrained environments. Combined with open agent frameworks and multi‑agent tooling, Phi‑4 variants make practical, deployable AI agents more accessible.